
13 Jun 2018
SQL Server
#deadlocak问题
Transaction (Process ID) was deadlocked on lock resources with another process and has been chosen as the deadlock victim.
问题描述
根据Excel上传的签收数据信息,更新数据库里的发货单信息。
首先根据Excel解析出来的数据流,逐条查询每个实体并进行更新操作,最后进行批量的更新。
解决问题的思路
失败的尝试
- 首先尝试降低事物隔离级别,改为
@Transactional(isolation = Isolation.READ_UNCOMMITTED) - select语句中有join,对所有table都设为不加锁
with nolock - select 查询语句上面加 更新锁
with updlock
成功的尝试
- 如果把select和update的数据量控制为1,则不发生死锁问题。
- 在update之前对数据进行排序,也不发生死锁问题。
分析问题
batch update的并发操作导致的死锁,update操作默认持有排它锁。比如事物A update的顺序是[1,2,3,4], 事物B update的顺序是[2,1,3,4],事物A 更新完1后尝试获取2的排它锁,但是2的排它锁被事物 B持有,并且事物B尝试获取1的排它锁,但是由于事物没有提交,都无法释放锁,出现循环等待,死锁也就产生了。
经验总结
最开始以为是select持有了共享锁,然后update的时候尝试获取排它锁导致的死锁,这是SQL Server常有的死锁情况。这里会有疑问,select并没有加任何的锁呀。。。这是SQL Server与MySQL的不同:
MS-SQL Server 使用以下资源锁模式。
锁模式 描述
- 共享 (S) 用于不更改或不更新数据的操作(只读操作),如 SELECT 语句。
- 更新 (U) 用于可更新的资源中。防止当多个会话在读取、锁定以及随后可能进行的资源更新时发生常见形式的死锁。
- 排它 (X) 用于数据修改操作,例如 INSERT、UPDATE 或 DELETE。确保不会同时同一资源进行多重更新。
- 意向锁 用于建立锁的层次结构。意向锁的类型为:意向共享 (IS)、意向排它 (IX) 以及与意向排它共享 (SIX)。
- 架构锁 在执行依赖于表架构的操作时使用。架构锁的类型为:架构修改 (Sch-M) 和架构稳定性 (Sch-S)。
- 大容量更新 (BU) 向表中大容量复制数据并指定了 TABLOCK 提示时使用。
共享锁
共享 (S) 锁允许并发事务读取 (SELECT) 一个资源。资源上存在共享 (S) 锁时,任何其它事务都不能修改数据。一旦已经读取数据,便立即释放资源上的共享 (S) 锁,除非将事务隔离级别设置为可重复读或更高级别,或者在事务生存周期内用锁定提示保留共享 (S) 锁。
更新锁
更新 (U) 锁可以防止通常形式的死锁。一般更新模式由一个事务组成,此事务读取记录,获取资源(页或行)的共享 (S) 锁,然后修改行,此操作要求锁转换为排它 (X) 锁。如果两个事务获得了资源上的共享模式锁,然后试图同时更新数据,则一个事务尝试将锁转换为排它 (X) 锁。共享模式到排它锁的转换必须等待一段时间,因为一个事务的排它锁与其它事务的共享模式锁不兼容;发生锁等待。第二个事务试图获取排它 (X) 锁以进行更新。由于两个事务都要转换为排它 (X) 锁,并且每个事务都等待另一个事务释放共享模式锁,因此发生死锁。
若要避免这种潜在的死锁问题,请使用更新 (U) 锁。一次只有一个事务可以获得资源的更新 (U) 锁。如果事务修改资源,则更新 (U) 锁转换为排它 (X) 锁。否则,锁转换为共享锁。
排它锁
排它 (X) 锁可以防止并发事务对资源进行访问。其它事务不能读取或修改排它 (X) 锁锁定的数据。
所以想要在select的时候就加排它锁,但是发现并不起作用。这是因为select语句是只对一条数据加锁成功,所以对于接下来的update语句没有起到加锁的作用。
因此解决办法有一下3种:
-
逐条select 然后update,减小锁的范围
优点:比较简单
缺点:IO较多,性能较慢 -
所有数据更新完毕后,插入前进行排序
优点:改动最小
缺点:代码不可读 -
批量查询,更新,然后update
优点:性能较高,IO最少 缺点:内存消耗可能会增大。但是鉴于之前的操作,如果数据不合法才会返回为null,内存可以被gc,因此只有在不合法数据较多的情况下才考虑两种操作内存开销的比较。
多线程测试代码
@Test
public void test() throws ExecutionException {
CompletableFuture[] results = IntStream.range(0, 20).mapToObj(i -> {
return runFF();
}).toArray(size -> new CompletableFuture[size]);
CompletableFuture.allOf(results).get();
}
private CompletableFuture<Void> runFF() {
return CompletableFuture.runAsync(() ->{
...
});
}
Shrink DB
数据库使用数据文件(扩展名是mdf 或 ndf)来存储数据,使用日志文件(扩展名是ldf)来存储事务日志,通常情况下,数据文件会持续增长,不会自动释放空闲空间,这样会导致硬盘空间耗尽。如果一个数据库的文件有很多空闲空间,收缩数据库文件是一种解决硬盘空间紧张的直接方式。在SQL Server中,我们可以使用 DBCC ShrinkFile命令收缩数据文件,该命令首先将文件尾部的区(extent)移动到文件的开头,文件结尾的空闲的硬盘空间被释放给操作系统,这种操作就像截断将文件的尾部一样,这种方式不需要消耗很多IO就能释放空间;但是,如果空闲部分不在文件末尾时,收缩操作必须扫描数据文件,并对正在读取的页面加锁,把文件末尾的区移动到文件开头,这是一个IO密集型的操作,影响数据库的性能,但是,收缩操作不是一个独占行为,在做文件收缩时,其他用户仍然可以对数据库进行读写操作。在任意一个时间点停止dbcc shrinkfile命令,任何已经完成的工作都将保留。
收缩 数据库 是非常耗费server性能的操作,如果没有必要不要收缩
go
收缩 无非就是把已经分配给数据库文件空间收回来,但是,收缩的时候 要移动数据页,而且可能造成大量的碎片,影响性能。 go
日志收缩和数据文件收缩不一样,日志中的虚拟文件状态 只有 在可复用 时候 才能收缩。 而且 凡是有活动的日志的日志虚拟文件都是活动的不能收缩。 go
首先尝试指定Truncate Only收缩方式.它只是移除文件尾部的空闲空间,并不重新组织已经使用的数据页。如果SQL Server在shrink data file时不移动数据,那么shrink 就不会产生碎片,对现有数据不会有影响。唯一不影响现有物理数据的情况是在执行DBCC Shrinkfile 命令时指定TruncateOnly选项,DBCC Shrink命令只将文件末尾的剩余空间释放,归还给OS。
Shrink a Database
decreases the size of the data and log files in the UserDB database and to allow for 10 percent free space in the database.
DBCC SHRINKDATABASE (UserDB, 10);
GO
shrink the size of a data file named DataFile1 in the UserDB database to 7 MB.
USE UserDB;
GO
DBCC SHRINKFILE (DataFile1, 7);
GO
JSON data in SQL Server
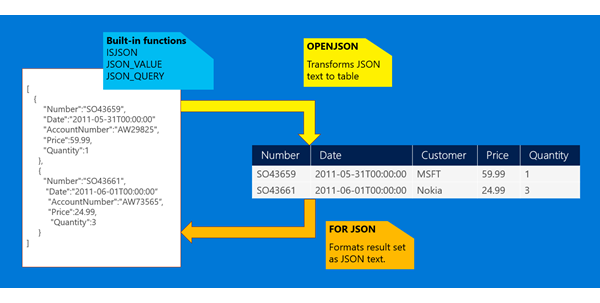
JSON_VALUE 读取 json 列 Data
SELECT
Name,
Price,
JSON_VALUE(Data, '$.Color') Color,
JSON_VALUE(Data, ‘$.StandardCost’) Cost,
JSON_VALUE(Data, '$.Class') Class
FROM ProductCatalog
WHERE JSON_VALUE(Data, '$.Color') = 'Black'
AND Price < 100
JSON_MODIFY 修改json 列 Data
UPDATE ProductCatalog
SET Data = JSON_MODIFY(Data, '$.Color', 'White')
WHERE JSON_VALUE(Data, '$.ProductNumber') = 'BK-R50R-60'
如果担心性能问题,那么与正常column一样,用索引即可。
如果日志是按json格式记录的,那么可以转化为报表
比如日志文件包含的格式如下:
{"type":"Debug","page":"user/delete","Time":"2016-02-04 4:58:51",...}
读出所有的日志:
SELECT log.*
FROM OPENROWSET(BULK N'c:\JSON\logANSI.txt',
FORMATFILE = 'c:\\JSON\ldjfmt.txt',
CODEPAGE = '65001') as log
通过OPENJSON函数读出所有的entry:
SELECT data.*
FROM OPENROWSET(BULK N'c:\JSON\logANSI.txt',
FORMATFILE = 'c:\\JSON\ldjfmt.txt',
CODEPAGE = '65001') as log
CROSS APPLY OPENJSON (log.log_entry)
WITH ( Page varchar(30),
[User] varchar(20),
Time datetime2,
Ip varchar(20) '$.Origin',
Duration bigint) as data
将数据库中数据读出为json
SELECT id, name as text, COALESCE(managerid, '#') as parent
FROM employee
order by managerid asc
FOR JSON PATH
Til next time,
at 16:44
