
17 Jun 2019
Linux 性能调优
Linux 性能调优
1 平均负载
当你用uptime查看系统的负载情况时,它每列分别表示 当前时间、系统运行时间、正在登录用户数、过去1,5,15分钟的平均负载。
# uptime
21:19:41 up 117 days, 6:38, 1 user, load average: 0.02, 0.05, 0.08
平均负载,指的是单位时间内,系统处于可运行状态(Running或者Runnable, ps命令中的R状态)和不可中断状态(uninterruptible sleep,ps命令中的D状态)的平均进程数,也就是平均活跃进程数。它和CPU使用率并没有直接关系。
平均负载最理想的情况是等于CPU的个数。CPU个数的查看可以从文件/proc/cpuinfo获取–grep 'model name' /proc/cpuinfo |wc -l。
时间1,5,15主要用于看趋势,趋势逐渐增加并且高于70%时,需要去分析排查原因。
计算平均负载时,不仅包含正在使用CPU的进程,还包括等待CPU和等待I/O的进程;CPU使用率是单位时间内CPU繁忙情况的统计。比如:
- CPU 密集型进程,它们就是正相关
- I/O密集型进程,等待I/O也会导致负载升高,但CPU使用率不一定很高
- 大量等待CPU的进程调度也会导致平均负载升高,此时的CPU使用率也会比较高。
测试及性能调优
stress 是Linux系统的常用压测工具。
sysstat包含了常用的Linux性能工具,用来监控和分析系统的性能。
对以上的三种情况分别进行测试:
-
CPU 密集型进程
// 模拟CPU密集型 # stress --cpu 1 --timeout 600 // 查看平均负载 # watch -d uptime // 查看CPU使用情况 # mpstat -P ALL 5 // 具体哪个进程导致CPU使用率很高 # pidstat -u 5 1 -
I/O密集型进程
// 模拟I/O密集型 # stress -i 1 --timeout 600 // 采用上面同样的方式,发现iowait特别高 -
大量进程的场景
# stress -c 8 --timeout 600 // 发现8个进程在争抢2个CPU,每个进程等待CPU的时间(也就是%wait列)高达75%。
2 CPU上下文切换
- 进程上下文切换
- 线程上下文切换
- 中断上下文切换
怎么查看系统的上下文切换
vmstat 查看系统总体的上下文切换情况
# vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 210660 140852 2055688 0 0 3 53 2 2 2 1 96 0 0
- cs – 每秒上下文切换的次数
- in – 每秒中断的次数
- r – 就绪队列的长度,也就是正在运行和等待CPU的进程数
- b – 处于不可中断睡眠状态的进程数
要查看每个进程的详细情况,pidstat -w。它默认显示进程的指标数据,加上-t参数后,才会输出线程的指标。
# pidstat -w 5
Linux 4.4.0-141-generic (suyue) 2019年06月17日 _x86_64_ (2 CPU)
22时21分23秒 UID PID cswch/s nvcswch/s Command
22时21分28秒 0 3 3.39 0.00 ksoftirqd/0
22时21分28秒 0 7 63.27 0.00 rcu_sched
- cswch – voluntary context switches 自愿上下文切换,进程无法获取所需资源,导致的上下文切换
- nvcswch – non voluntary context switches 非自愿上下文切换,进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。
测试及性能调优
可以用sysbench来模拟系统多线程调度的情况。它是一个多线程的基准测试工具,一般用来评估不同系统参数下的数据库负载情况。
#sysbench --threads=10 --max-time=300 threads run
通过以上工具发现中断次数上升到一万左右,pidstat是个进程性能分析工具,中断发生在内核态,所以并不能通过它分析出来。而是通过 /proc/interrupts这个只读文件中读取。/proc实际上是Linux的一个虚拟文件系统,用于内核空间与用户空间的通信。/proc/interrupts就是这种通信机制的一部分,提供了一个只读的中断使用情况。
# watch -d cat /proc/interrupts
发现变化速度最快的是重调度中断(RES),这个中断类型表示,唤醒空闲状态的CPU来调度新的任务运行。这是多处理器系统(SMP)中,调度器用来分散任务到不同CPU的机制,通常也被称为处理器间中断(Inter-Processer Interrupts, IPI)。所以这里的中断升高还是因为过多任务的调度问题。
3 CPU使用率
CPU使用率,指的是单位时间内,CPU使用情况的统计。
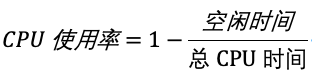

为了统计CPU使用时间,Linux系统定义了节拍率(HZ)。
# grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=250
但它是内核选项,所以用户空间程序并不能直接访问,为了方便用户空间程序,内核还提供了用户空间节拍率(USER_HZ),固定为100,也就是1/100秒。
Linux通过/proc虚拟文件系统,向用户空间提供了系统内部状态的信息,而/proc/stat提供的就是系统的CPU和任务统计信息。
cat /proc/stat | grep ^cpu
cpu 41827554 83278 25483921 1942373131 4082146 0 1525662 0 0 0
cpu0 20948898 42210 12729234 971013070 2127290 0 745506 0 0 0
cpu1 20878655 41067 12754686 971360060 1954855 0 780156 0 0 0
# man proc 查看每列的含义
进程的CPU使用率统计,在/proc/[pid]/stat
如何查看CPU使用率
- top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。top 默认显示的是所有 CPU 的平均值,这个时候你只需要按下数字 1 ,就可以切换到每个 CPU 的使用率了。
- ps 则只显示了每个进程的资源使用情况。
top 并没有细分进程的用户态 CPU 和内核态 CPU。那要怎么查看每个进程的详细情况呢?
# pidstat 1 5
Linux 4.4.0-141-generic (suyue) 2019年06月18日 _x86_64_ (2 CPU)
23时41分52秒 UID PID %usr %system %guest %CPU CPU Command
23时41分53秒 0 204 0.00 0.99 0.00 0.99 1 systemd-journal
23时41分53秒 0 1052 0.99 0.00 0.00 0.99 0 etcd
23时41分53秒 0 1854 0.99 0.00 0.00 0.99 0 kube-apiserver
23时41分53秒 0 2061 0.99 0.99 0.00 1.98 1 kubelet
23时41分53秒 0 2678 0.99 0.99 0.00 1.98 1 kube-controller
23时41分53秒 0 2679 0.99 0.99 0.00 1.98 0 kube-scheduler
测试及性能调优
-
ab 作为压测工具
ab -c 10 -n 10000 http://10.240.0.5:10000/ - top 查看哪个进程占用CPU较多
-
perf top 查看进程的哪个函数导致的
// -g 开启调用关系分析,-p 指定进程号 21515 # perf top -g -p 21515按方向键切换到 php-fpm,再按下回车键展开 php-fpm 的调用关系,你会发现,调用关系最终到了 sqrt 和 add_function。
// 使用 grep 查找函数调用 # grep sqrt -r app/ # 找到了 sqrt 调用 app/index.php: $x += sqrt($x); # grep add_function -r app/ # 没找到 add_function 调用,这其实是 PHP 内置函数
Til next time,
at 09:42
